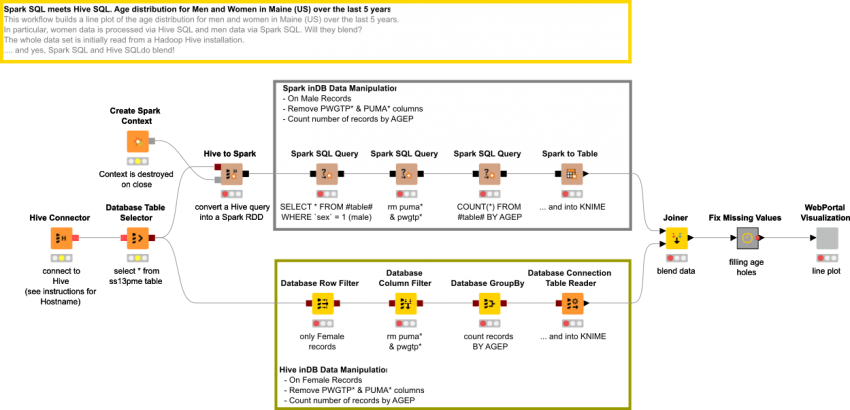
This workflow builds a line plot of the age distribution for men and women in Maine (US) over the last 5 years. In particular, women data is processed via Hive SQL and men data via Spark SQL. Will they blend? The whole data set is initially read from a Hadoop Hive installation. .... and yes, Spark SQL and Hive SQLdo blend!
Resources
EXAMPLES Server: 10_Big_Data/02_Spark_Executor/07_SparkSQL_meets_HiveQL10_Big_Data/02_Spark_Executor/07_SparkSQL_meets_HiveQL*
Download a zip-archive
Blog:
* Find more about the Examples Server here.
The link will open the workflow directly in KNIME Analytics Platform (requirements: Windows; KNIME Analytics Platform must be installed with the Installer version 3.2.0 or higher). In other cases, please use the link to a zip-archive or open the provided path manually